



GitOps is a modern way to manage cloud-native systems that are powered by Kubernetes. It leverages a policy-as-code approach to define and manage every layer of the modern application stack - infrastructure, networking, application code, and the GitOps pipeline itself.
-- Weaveworks
GitOps as a concept was established in 2017 by Weaveworks and has since been widely adopted in software delivery with a growing number of CNCF tools being developed around it.
While at AirQo, I've had the opportunity of working in both traditional and GitOps environments and in this article, I share experience from a DevOps perspective after having made the shift in our delivery pipeline.
Some bit of context
AirQo is a cleantech startup whose vision is clean air for all African cities. A key duty in getting there is availing our users with Africa's air quality information and so we have a number software products ranging from mobile applications, web applications, and an API just for that. Our API relies on a couple of microservices in the backend to transform the Particulate Matter(PM) data collected by our air quality monitors into consumption-ready information. We run our microservices on some few Kubernetes(k8s) clusters.
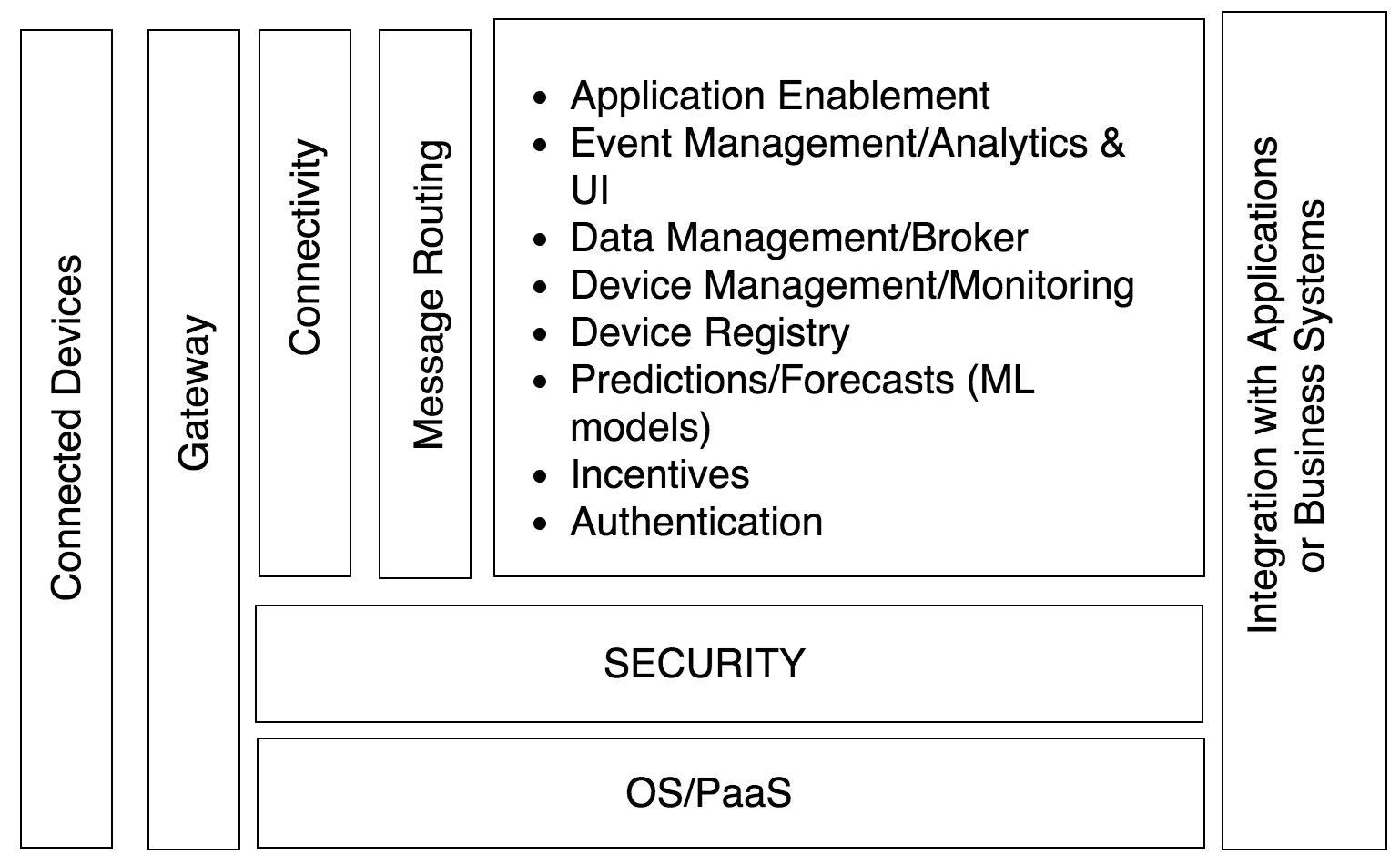 |
| Architectural diagram |
We use a Gitflow worflow in our mono-repository with all the products and the corresponding k8s manifests in the same repo.
Initial setup
In the early days, our continuous delivery pipeline had both the integration and deployment done by the same tool, GitHub Actions. All application images pointed to the "latest" tag in within k8s configurations thus it was the de facto for all applications restarts. GitHub Actions built and pushed the images to Google Container Registry(GCR), but was did not update the corresponding k8s manifest with the new image tag despite the fact that it was the uniquely identifiable image tag(e.g prod-docs-123abc). This meant that the deployed state was always divergent from the state on GitHub at the image tag level at least. Some of the challenges we faced include;
- Difficulty in telling the actual resource definition of applications on the cluster.
There were times when quick/minor fixes were made to applications directly through kubectl without going through the git workflow. It was difficult for the rest of the team to know of such changes given that they were rarely communicated or committed to GitHub. Not to mention that the image tag was obviously one of such application properties we weren't sure about. - The development team lacked visibility into their applications.
Most development team members weren't conversant with k8s and kubectl commands to for instance view live application logs whenever need arose. This made troubleshooting unnecessarily a step longer given since a DevOps engineer was needed to retrieve the logs and thus, - A larger workload for the operations team given that it was an operations-centric approach.
- Operations engineers always had to have access to the clusters via a kubeconfig in order to carry out even very basic tasks.
- Rolling back changes was more technical than necessary. Given that we defaulted to the latest tag on GitHub. A DevOps engineer had to get the image tag of a previous application version from GCR, then run a
kubectl patchcommand to update the application image tag with a previous one.
How we got there
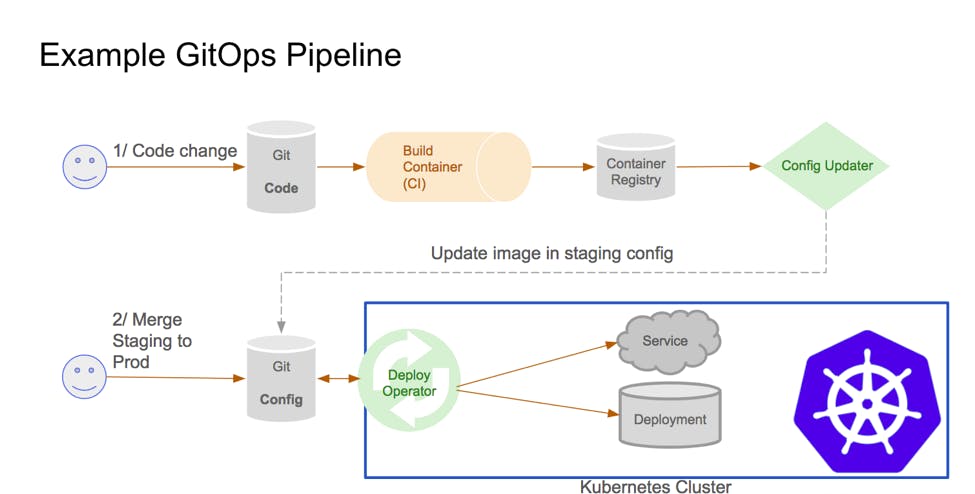
A mono-repository setup can present some challenges and we faced one ourselves with the different products' delivery pipelines to production getting intertwined; deeming it impossible to deploy a specific product at a time. The CI/CD pipelines were all dependent on the git workflow and thus had the same trigger. Perhaps I can discuss how we went about in another article but during my search for an alternative autonomous trigger, is when I landed on ArgoCD. Up until then, I had miniature knowledge of GitOps but I found it interesting as I read about it. Fascinated by how the methodology would address many challenges we faced, I instantly installed ArgoCD on one of our clusters. Due to it's multi-tenant nature, I was able to add setup applications in the different clusters and their respective projects under one roof: and subsequently on boarded the entire team onto it. We now use ArgoCD as our deploy operator but kept GitHub Actions as our CI tool and Config Updater for image tags on Helm(which we defaulted to).
ArgoCD removed pain points
- With ArgoCD, we are notified via slack whenever the state of the deployed application diverges from the state on GitHub. The states are also automatically synced to match the GitHub definition in line with the GitOps principle of Git as the source of truth. This ensures that changes are documented on GitHub as a bare minimum.
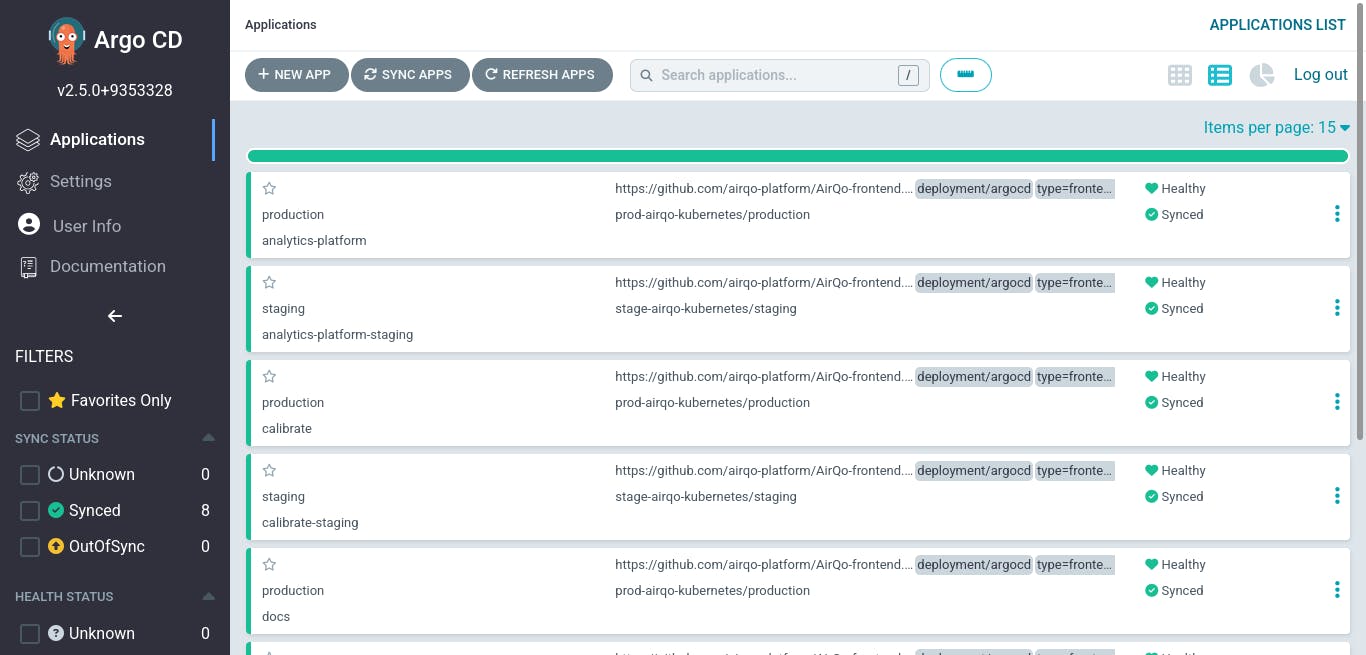
- The development team is now able to self serve on anything to do with their applications. The ArgoCD UI is so intuitive that they can carry out tasks ranging from creating new applications to accessing logs of existing ones without assistance from the operations team. A more developer-centric approach.
- Rollbacks are now much easier. It's now a matter of reverting changes on the GitHub repo and an older image tag will be deployed automatically.
- As the DevOps engineer, I am now able to run basic operations on the clusters without using and scripting commands. For instance, I can view health statuses of all applications on the clusters at the comfort of my phone, without running any commands to switch cluster context.
Final words
Our adoption of GitOps is recent but I can definitely tell that there's a lot we have to benefit from it at AirQo as we continue to explore it. I thus generally believe that what I've shared here is only but the surface and trust that you and your organisation could discovered that this methodology solves challenges you had gotten accustomed when you try it.
Until next time... Happy hacking
Further reading